
type
status
date
slug
summary
tags
category
icon
password
定义
- 针对输入及输出的生成内容的事实(fact)或知识(knowledge)进行验证,判断其是否:
- 忠于现实
- 事实自洽(输入与输出事实一致、输出内容事实一致)
- 对输入及生成内容中不符合要求的内容进行调整
- 输入调整:query改写
- 输出调整:内容修改、抛弃或重新生成
指标
- KF1(https://arxiv.org/pdf/2104.07567.pdf):knowledge F1,即针对token级别的知识片段和生成答案间的重叠计算F1
- 根据性(LaMDA: https://arxiv.org/pdf/2201.08239.pdf,https://zhuanlan.zhihu.com/p/616631258)
- Groundedness: 包含对外部世界内容主张(claims)的生成内容中,可以被权威外部来源支持的比例
- Informativeness: 带有外部来源支持的生成内容在所有生成内容中的占比(仅和groundedness分母不同)
- Citation accuracy: 带引用的生成内容占比(不包括常识,如“马有四条腿”)
- 测试集构建(40k对话):
- 针对回答是否包含外部世界主张进行打分,不包括不为人知的人物(如:I baked three cakes last week)的相关回答
- 判断事实主张是否正确(超过3个标注人员认为正确则作为常识,不需要检查是否被外部信源check)
- 针对需要外部信源check的,标注人员给出对应用于检查的检索query
- 最后根据外部信源的结果修改模型回答,若检索结果来自开放网络,则给出引用URL
- 事实/知识编辑指标(Mass Editing Memory in a Transformer: https://arxiv.org/abs/2210.07229)(这个可以用来评估原始候选回答和知识增强后回答的有效或偏离程度):
- Efficacy Success (ES) :编辑成功分数(指 在生成中,新目标词的概率>原目标词的概率)
- Paraphrase Success (PS):同义表达成功分数(指 对修改的知识进行相同意思不同形式的表达,仍然成功的比例)
- Neighborhood Success (NS):非同义保持成功分数(指 对修改的知识进行不同意思相同形式的表达,没有被修改的比例)
- 上述三个方面指标的调和平均数,称为 Editing Score (S)(编辑分数),用于整体衡量编辑的效果。
方法
模型知识正确性提升
- 借助外部检索系统过滤+重新生成(LaMDA)
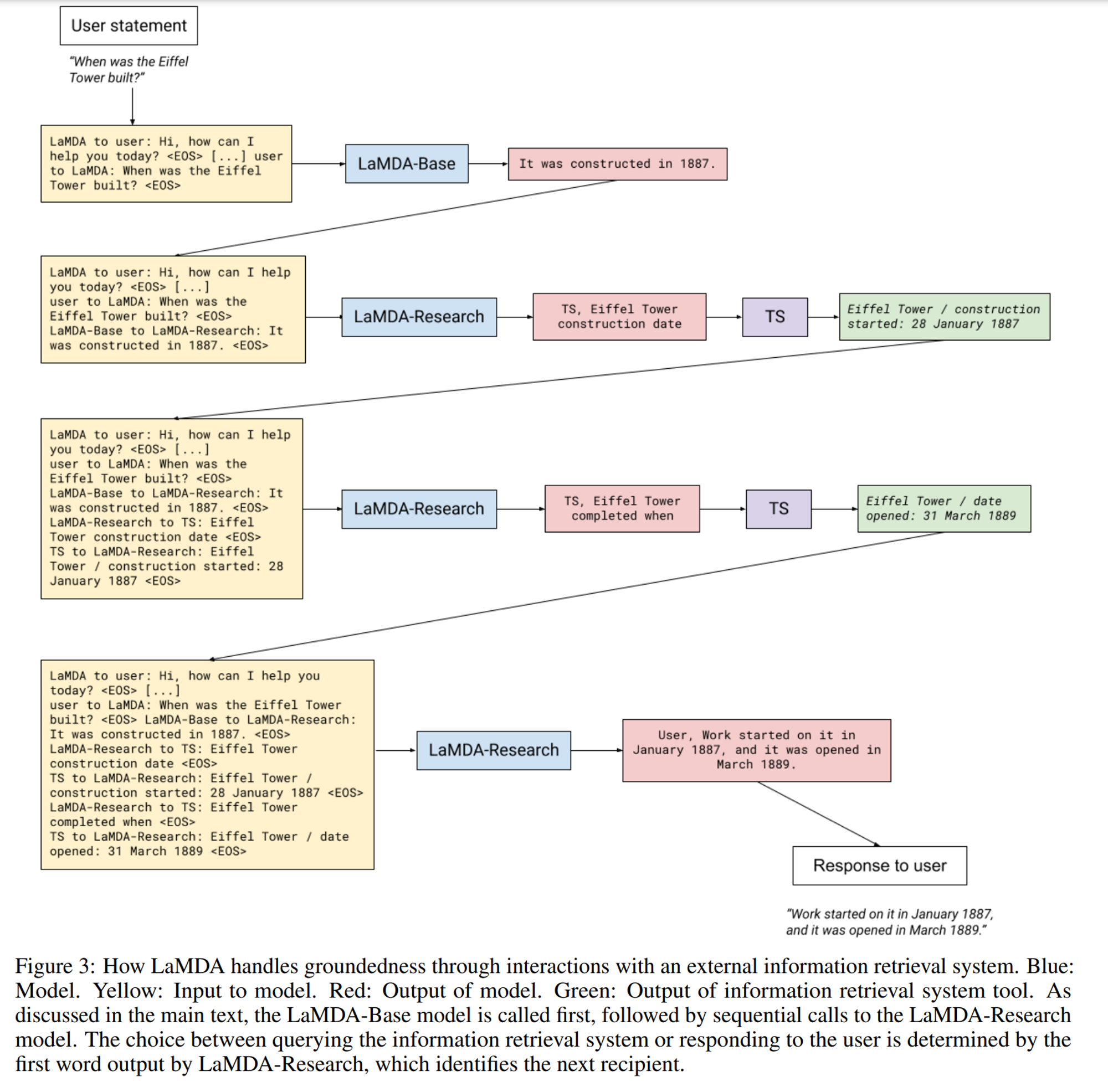
- 训练llm使用工具(toolset,类似toolformer/langchain),主要为信息检索、计算器和翻译工具。在base模型的基础上训练一个LaMDA-Research模型,使用base模型的生成结果作为输入,针对里头的事实声明向TS(toolset)发起信息检索(事实过滤),根据TS返回的多条结果+原始上下文+base模型结果重新生成经过事实验证的内容(重新生成)。
- WebGPT(https://arxiv.org/abs/2112.09332,https://finisky.github.io/webgpt-summary/):做得更彻底,信息检索系统是一个文本web浏览器(Bing Search API),模拟了人使用搜索的点击、翻页等行为,而非仅使用query response(即模型的action并非仅有单纯的文字输出)。其中human-feedback对模型效果提升至关重要,这也是和LaMDA工作的最大区别。
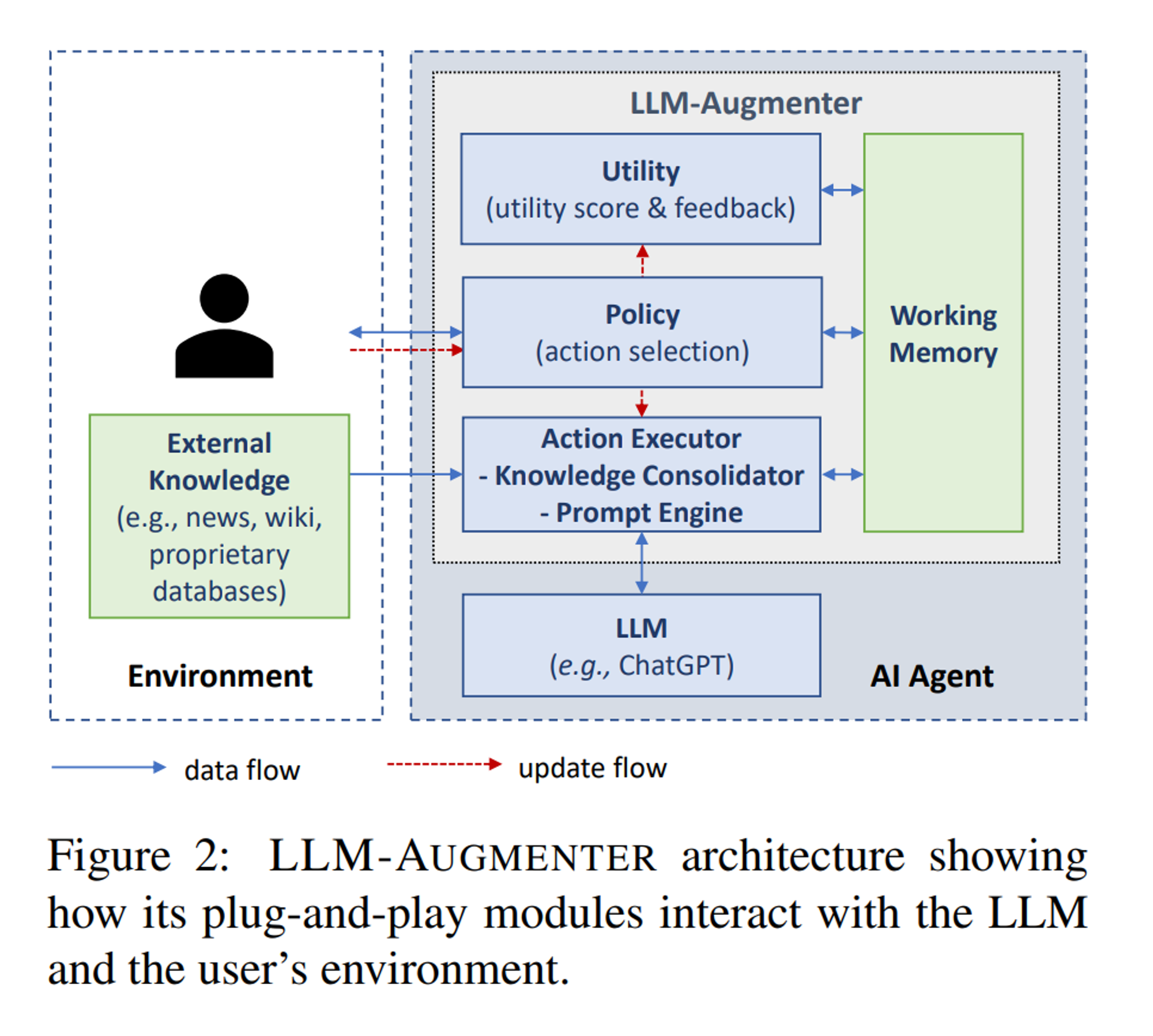
- Check Your Facts and Try Again: Improving Large Language Models with Automated Feedback(https://arxiv.org/abs/2302.12813):来自微软23年的工作,最大的贡献在于所谓的auto feadback和完整的策略系统(LLM-Augmenter,第二张图)。
- 生成答案的prompt包含:原始query、对话历史、证据(来自知识集成模块)、反馈feedback(来自效用模块)。同时prompt与任务相关,即存在多套prompt。
- 知识集成模块(Knowledge Consolidator),相比之前的工作中的信息检索功能外,还增加了NEL(entity linker)和证据链接器(evidence chainer)两部分。具体来说为:
- 根据原始query和对话历史,生成一些检索query,检索这批query拿到的结果作为原始证据
- 将原始证据中的实体关联对应的描述信息(e.g. wiki),构造一个或多个证据图
- 证据链接器将不相关的证据从图中去除,构造与query最相关的最短证据路径,放入working memory中
- 效用模块(Utility)主要产出给定回答的效用分数和反馈(一段文本),主要是使用和对话情景相关的效用函数(utility functions)(论文中的实验只用了一种效用函数),来调整生成的prompt。
- model-based utility functions:一般给出不同维度的偏好分数,如流畅度、信息量、真实性。通过收集来的人类偏好数据或日志训练得来
- rule-based utility functions:启发式或人为设定的规则。
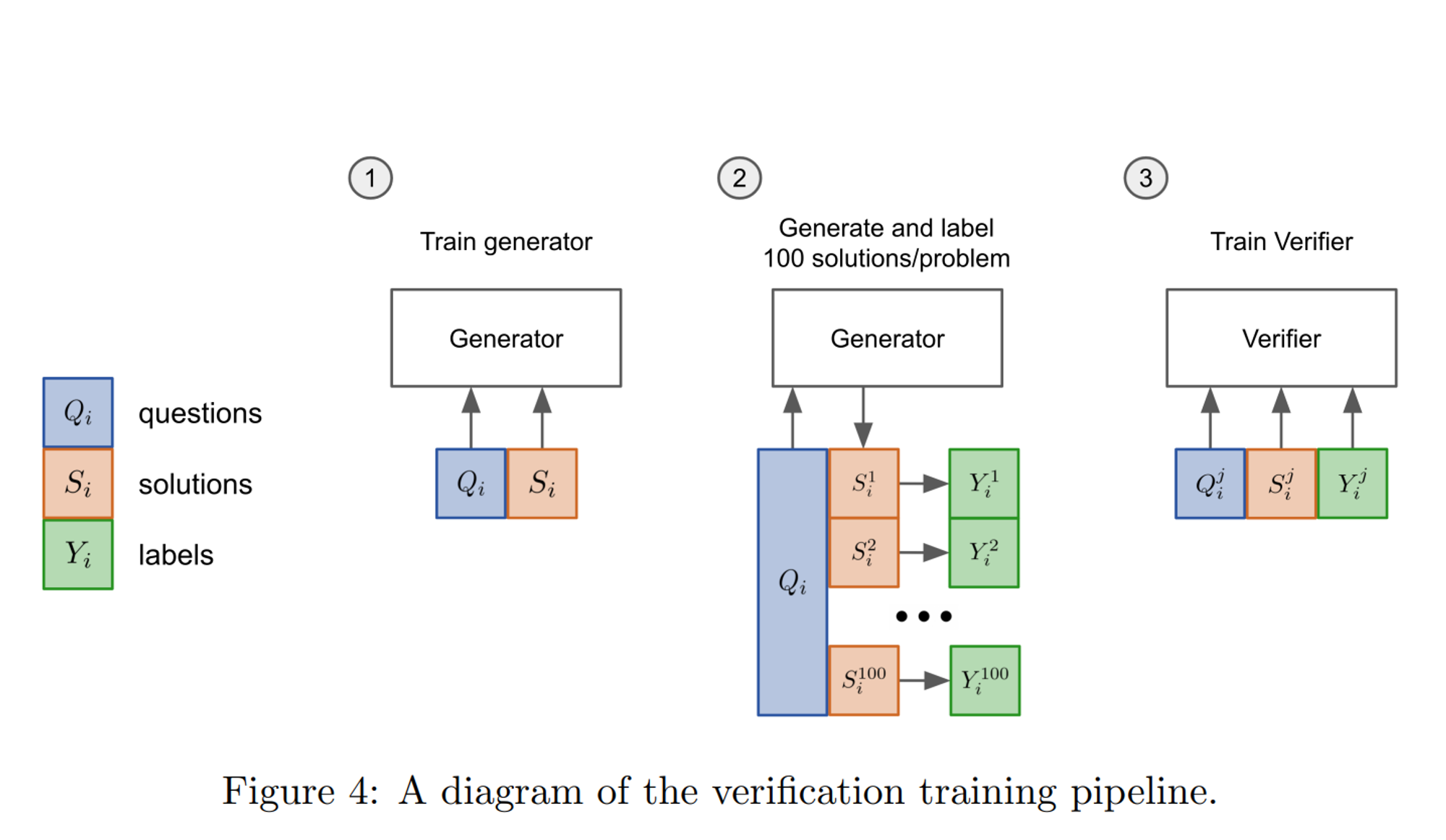
- 训练llm作为验证器打分(Training Verifiers to Solve Math Word Problems, https://arxiv.org/pdf/2110.14168.pdf)
- OpenAI在21年的工作,主要用于数学推理领域。思路有点像GAN,在开放知识领域可能没太大参考价值,没细看
- Fine-tuning with constraints (带限制的微调)
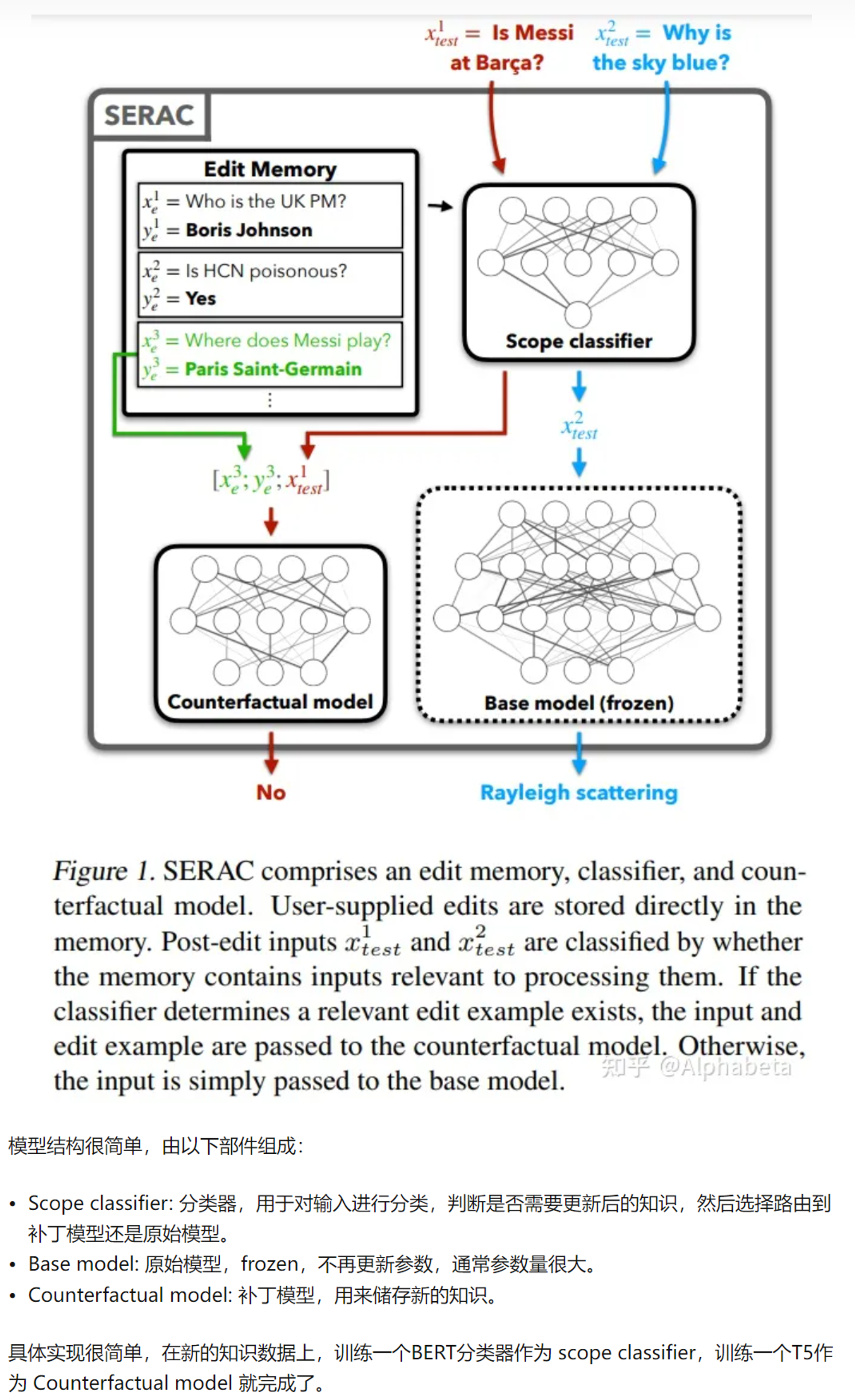
- Modifying Memories in Transformer Models(https://arxiv.org/abs/2012.00363):
- Memory-Augmented (retrieval) (检索内存增强)
- Memory-Based Model Editing at Scale(https://arxiv.org/abs/2206.06520)
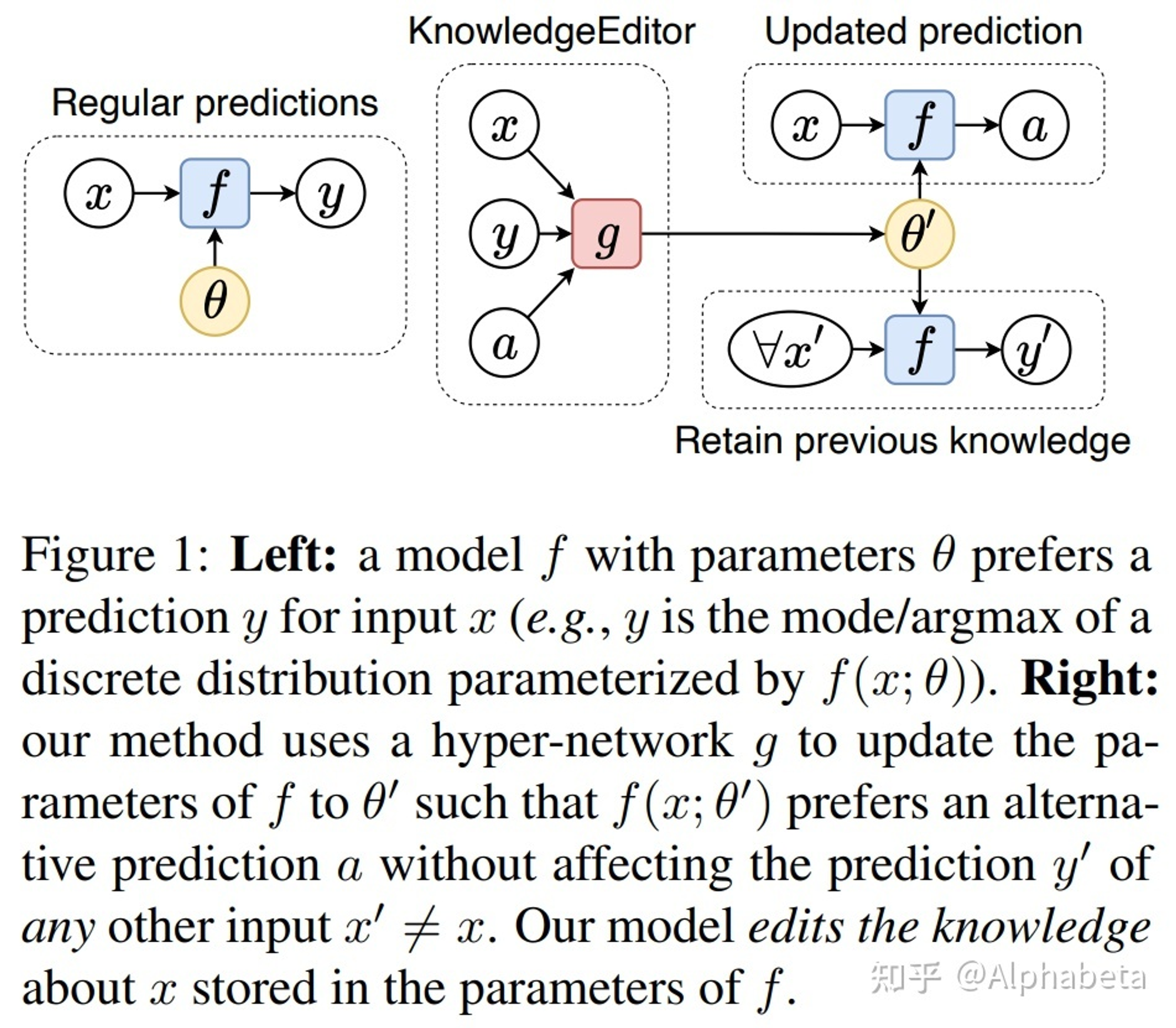
- Hyper network (超网络):持续输入知识,持续更新模型,而不希望重新训练或fine-tuning
- Editing Factual Knowledge in Language Models(https://arxiv.org/abs/2104.08164)
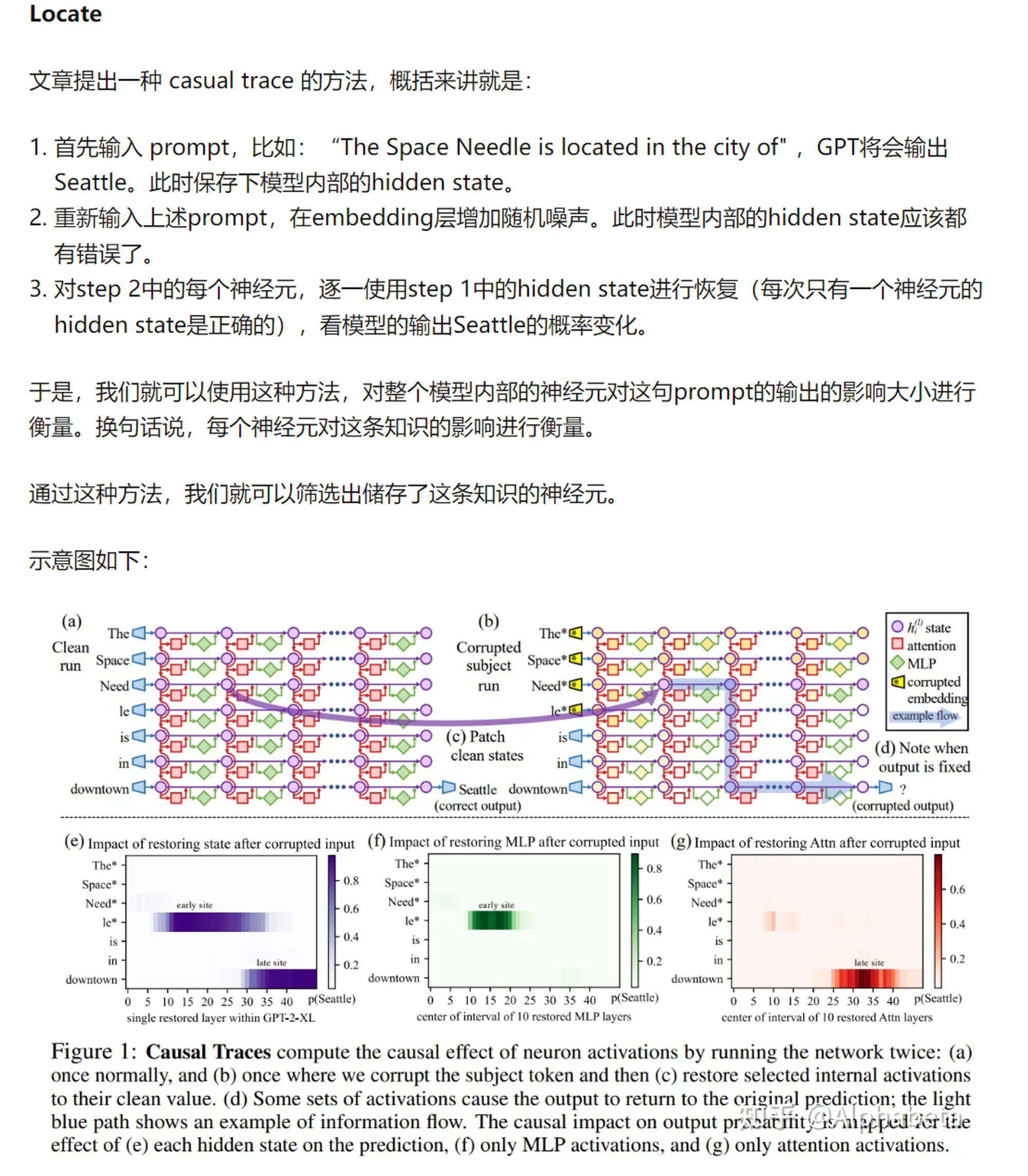
- Locate and edit (定位并修改):一种更偏向可解释性的想法为:transformer 的MLP层其实是key-value memory。(注:之前看过BERT上有类似的实验,寻找a/an等token与哪几个MLP神经元最相关,感觉比较玄学)
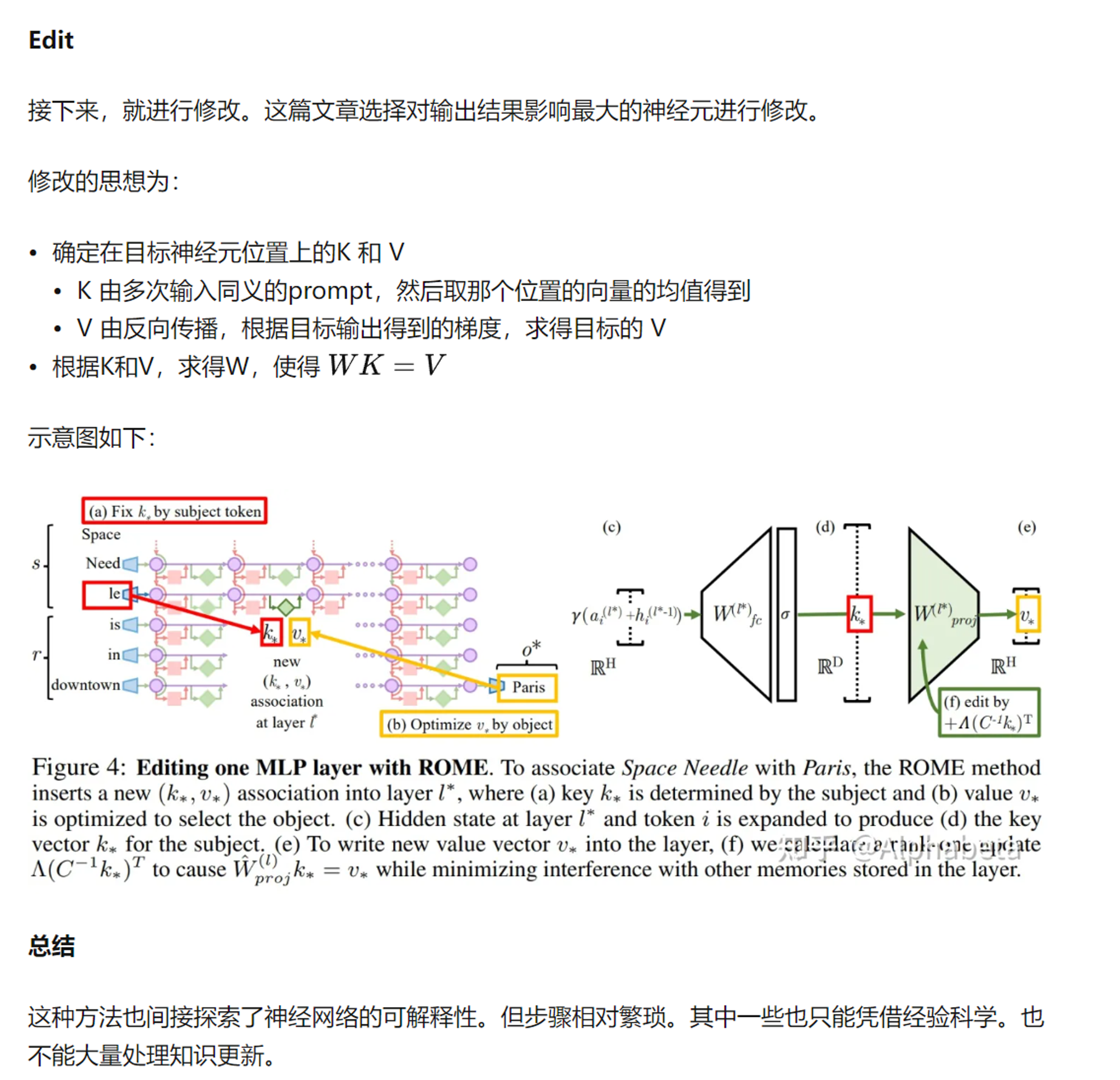
- Locating and Editing Factual Associations in GPT(https://arxiv.org/abs/2202.05262,https://zhuanlan.zhihu.com/p/606898174)
- 生成内容的知识正确性提升(即幻觉消除),思路上可以借鉴Knowledge Grounded Conversation(KGC)做法,即基于知识的对话生成。
- Open-domain Question Answering via Chain of Reasoning over Heterogeneous Knowledge(https://arxiv.org/abs/2210.12338)
借助搜索结果提升开放域QA的可靠性这个思路,还有后续不少探索的工作:
论文中提出的效用函数实现为语言模型,输入为用户query、证据、候选回答和对话历史,输出的为反馈文本(注:这里没有提到效用分数,可能只是用来做截断)

模型知识编辑
这个方向的工作,除了Memory-Augmented (retrieval)方式感觉不是很实用,迭代比较困难。
https://zhuanlan.zhihu.com/p/609177437


附录
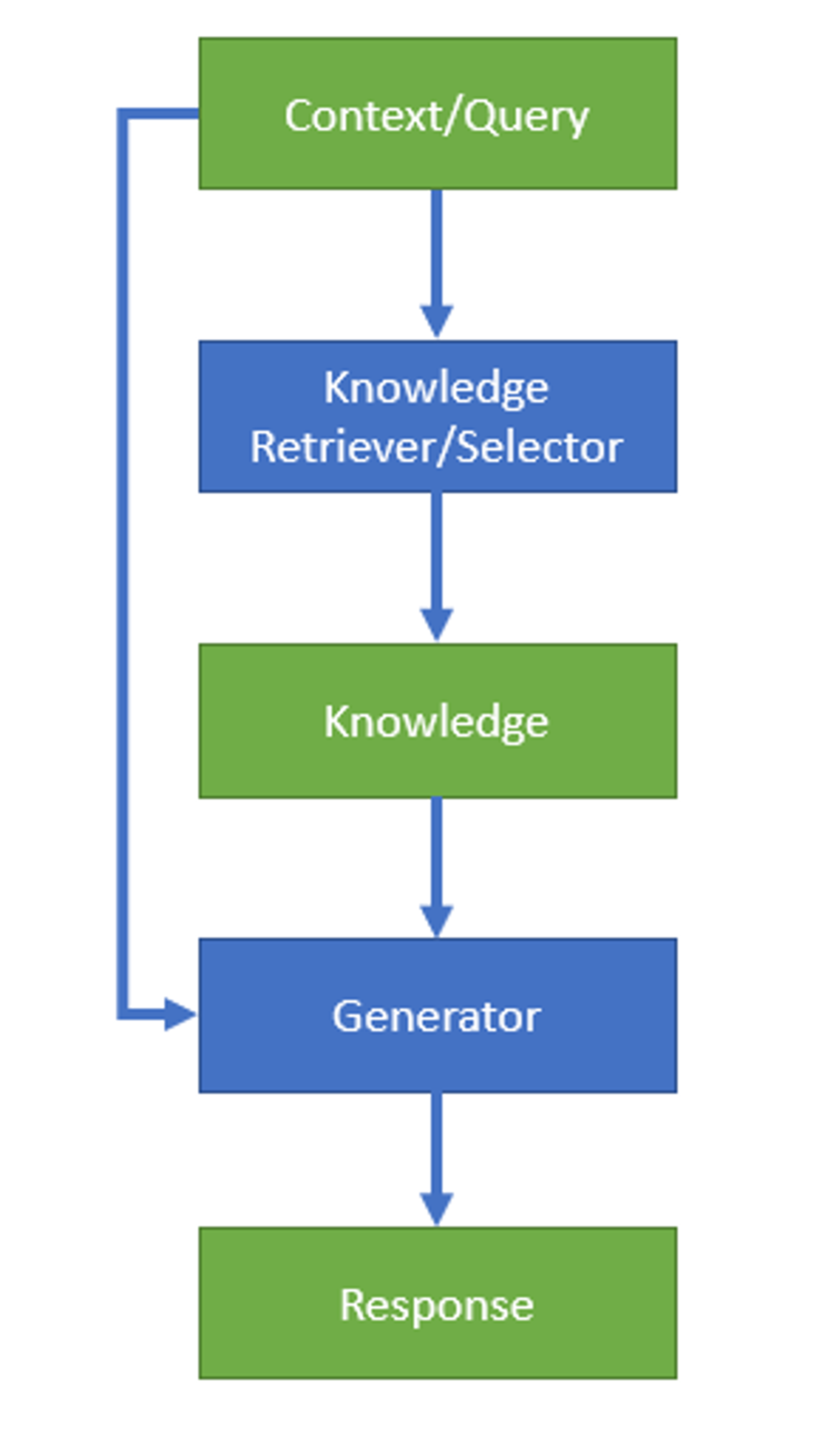
这篇博客介绍了一些近年来的工作,以围绕knowledge selection/retriever的优化为主
- 作者:hackaday
- 链接:https://openai.win/article/llm-a177772c6094439d8325e39b94fd3314
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。



